
PuppetDB. It has to happen this weekend for timing reasons. Plus, on top of that, I want to start writing about a proposal for an NIST project that I’m drafting because I think I’ve solved the problem they’re defining on the project page and want to solicit for community peer review. By Monday, I’m going to have orchestration in place to begin building out the SILO SDLC and get the schedule back on track.
The week after next I’ll be going to clip out the venting and remove the dead end paths taken, and create a step by step guide on setting up PuppetDB in a linear fashion. I’ve decided to take a more humble approach based on some observations I’ll discuss later, and the fact that on reflection, my confusion over packages versus modules was because puppet has used the word packages as a subcommand internal to puppet (but also uses the system package manager in a magic™ way), and not really being aware of this, I was quite confused about what they were saying.
Went to a LOPSA event. Very fun. It was good to get away from the keyboard for a while and socialize with somewhat similarly interested people. I’ve been buried in it for a while between various projects. So, they did this thing called ‘story time’ where they asked about a frustrating experience as a systems administrator. Sensing a soapbox, I was ready to tell my story, but when I asked about PuppetDB only like two people used it that would admit it, it sounded like there were mostly ansible and SCCM shops in representation, so I opted out and got with them privately. They provided some great insights.
I’m on a mission. When I’ve set out to do something, I will more than likely eventually find a way to do it.
PuppetDB and you
or
WHY I Learned to stop worrying and love the vm
So, this PuppetDB adventure’s been a bumpy ride. Some givens are that the documentation is poorly structured, vaguely written, and they want you to use a VM to learn where everything is. Which is weird, but, I need to work with it if I’m going to get past this hurdle, and it’s time to shut up and figure this out. It is my understanding that this is the most difficult part of the entire process and that it’s much easier to use than to install the optional components, which gives me the inspiration I need to finish this up this weekend.
I’ve got the VM downloaded and am going through it now and taking some notes which I’ll compile here in larger batches.
It’s a zip file. lol.
unzip lol.zip
Got it unzipped and there’s a readme file. It’s in rich text format, which I was not aware was still in use. geany can’t parse RTF files and neither can atom so now I am searching for a text editor that can still display rtf. I suspect they were tailoring the VM for windows users who’d generally open it with wordpad, which does support RTF.
Used this online legacy RTF file viewer and got a format error.
Still trying. God, give me patience. Every step along the way so far has been like this.
I eventually said fuck it and converted the RTF to PDF, and I am now “DTF”.
To save you some trouble I’ve uploaded the resulting PDF here and will be linking to it in the final condensed guide:
https://silogroup.org/puppet/puppet_vm_readme.pdf
I would suggest instead that they provide Markdown files instead of RTF.
Note: While I was tinkering I found a great commandline tool called pygmentize. It’s like cat but provides syntax highlighting. It is quite nice when aliased to ccat. There is also an alternative called vimcat that I want to check out as I suspect without getting a chance to dive through it yet may actually be using the syntax highlighting files in the system’s vim installation, which makes it way cooler. Less configuration management points++. As a frequent vim user this idea rocks my world.
Alright, good thing I checked the readme file. It looks like there were a couple defects in the VM image provided, so instead of updating the image they had the user make the changes before starting the VM and then change course for instruction errors in the guide after starting it.
Following those instructions now I will try to come up with a way to affordably host the new appliance after exporting.
Fix the RAM settings at 4096 MB. Set the network adapter to bridged mode, and use the “autodetect inferface” settings in your virtualbox settings for this VM.
There will be some minor adjustments to the tutorial once it’s boot.
Hit the new machine’s IP and you should see a “Quest Guide v1.2.5” load.
The machine itself tells you to SSH to it as root (really) with a statically set password (really).

Watch out for input capture. You need to hit the host key to get out of it. In my distribution it was the right control key. We used to use virtualbox for WDS image maintenance and syspreps back at one of my old gigs and it was always funny watching the other engineers freak out the first time and reboot their systems because they didn’t read the docs (on a windows system there is no framebuffer console to drop to).
I’ll be skipping anything related to the graphical web console or application orchestration tool as these are exclusive to the enterprise version nope they make you do it.
Intermission
So, to get started, use the quest command:
root@learning:~ # quest begin welcome You have started the welcome quest. root@learning:~ #
Of course, it doesn’t start the walkthrough in the terminal. Still bouncing windows.
Guide runs you through some basic commands:
root@learning:~ # puppet -V 4.5.3 root@learning:~ #
Ah. Ok, so it looks like quest is a gamification technique. It gives you action items to do, as you meet them it finishes them.
I need to find a potion shop. The layout of the guide and the quest game kind of reminds me of the security wargames archive at overthewire:
https://overthewire.org/wargames/
Now those were fun.
Creepily enough, when I started the quest “power_of_puppet”, quest remembered that I’d used facter ipaddress to get the IP of the machine as I was reading the readme, before I’d started the quest. I think they might be showcasing some user action auditing features there.
So, like git, and etckeeper previously blogged about, it looks like puppet is used as a command that provides access to modules, or, subcommands that provide modular functionality.
puppet module search graphite
Will let you search for modules matching “graphite” from the commandline from their public repository, puppet forge.
root@learning:~ # puppet module install dwerder-graphite -v 5.16.1 Notice: Preparing to install into /etc/puppetlabs/code/environments/production/modules ... Notice: Downloading from https://forgeapi.puppetlabs.com ... Notice: Installing -- do not interrupt ... /etc/puppetlabs/code/environments/production/modules └─┬ dwerder-graphite (v5.16.1) └── puppetlabs-stdlib (v4.7.0) root@learning:~ #
While they used good judgment in specifying the version manually to ensure compatibility with the guide, it is a documentation mistake to be using any information or concept not obtained by the user at that point in the walkthrough. So let’s get the version that was used for the -v value.
Note: I am seeing that there is a subcommand help and man, but using puppet man module gives you a man page that reminds me of the older manpages from like…. powershell, it just looks like a text file in less, I would like to see future versions use $PATH binaries for the subcommands and rely on the OS’ man system and man formatting conventions for these as they’re generally more familiar to any users who’d be going through these steps.
Well, okay, foot in mouth, I’m not seeing a way to figure out what versions are available for a module available in puppet forge. This will be problematic later as I intend to version lock critical services on my systems, so I’ll need to come back to it as during the setting in of services I’ll want to be able to check what versions of which components are available to reduce some back and forth.
So we’ve installed graphite using the puppet module tool. Next we’ll want to trigger a puppet agent to run for installation and configuration.
And…..shit. The very first quest is now telling me I have to use an enterprise-only feature, the PE Console, to continue, and I’ll bet skipping it will invalidate most of the future quests. I totally knew it was too good to be true.
Do I even still want to use this?
Ok, guess we’re not skipping the web UI console for the sake of finishing this article series before doing another look around for competing products.
https://admin:puppetlabs@$VM_IP_ADDRESS
Create a node group titled “Learning VM”. Node groups are basically just logical taxonomy for your servers allowing you to have different configurations for different server types.
In the left panel click node->classification and then click the link Add group...
They must have updated their interface without updating the doc–where it says to click “Add Group” after entering the name, you actually click “Add group…” as I’d previously said, then enter the name under “Group name”, and then click the button that says “Add”. This will add the new group to the list of node group names below. Click the group name in the updated table.
From here use the pin specific nodes link. What’s going on here, is the facter tool we looked at in the last episode is being used as a data source for rules in the PE console to classify the hosts running the agents based on matches to items returned in the catalog that facter is generating. The way the interface is designed it appears they wanted that to be the primary means of group classification. Pretty groovy. I’ll probably never use that feature to maintain infrastructure coherency, but it’s neat. I could see that being useful if I had thousands of nodes serving different purposes.
Terrifyingly confusingly though, on the pin specific nodes section of the form, they use “Certname” for the table header, which is liable to confuse the ever loving shit out of anyone whose ever looked at anything besides puppet before.
Deep breath.
They want you to put the name of the node there.
So before it can be available here, they want you to use the puppet agent on the VM to “check in” with the puppet master. Because it’s so mysterious and cool and magic from not being configured to do that by the user at this point, making them wonder how it knew to do that so they can reproduce it during go-live even if they did have an enterprise license at this point.

…Run the agent. Assume they’ll get to it.
root@learning:~ # puppet agent -t Info: Using configured environment 'production' Info: Retrieving pluginfacts Info: Retrieving plugin Info: Loading facts Info: Caching catalog for learning.puppetlabs.vm Info: Applying configuration version '1475417500' Notice: /Stage[main]/Puppet_enterprise::Puppetdb/File[/var/log/puppetlabs/puppetdb/puppetdb.log]/mode: mode changed '0644' to '0640' Notice: Applied catalog in 12.60 seconds
Immediately populates a name I didn’t give it in the hostnames certnamesadd pin to the group. Select it and click “pin node”, and then commit the change.
(I don’t have any intention of going enterprise for this build out so why am I stuck in the PE Console? I don’t want or need to learn this yet)
Anyway, when I ran the earlier command to install the dwerder-graphite module, it had a hook in it that registered a class named “graphite” with the puppet system. Since the object of this lesson is to trigger a run of an agent to install graphite, this seems relevant, though, it hasn’t been explained yet what the purpose of classes are making this currently to be flying blindly under instruction.
Click the “Classes” tab in the form for the “Learning VM” node group that was created earlier. It’ll autofill if you’ve followed this guide. Click “Add Class”.
At this point my best shot in the dark about the purpose of classes is that it’s a set of configurations and actions to apply to a node group, as a kind of evolutionary descendant of a package manager and configurator. So it would install the module that registered the class using parameters accounted for by the module creator that will be used in the logic of the post-install configuration. I don’t know if that’s accurate or not yet, so, pretty uncomfortable with this part.
In this machine’s instance, there is already an apache instance running on the VM that the module can account for and integrate graphite with during installation. There is also a django version compatibility issue with graphite that the author of the module was able to compensate for, all of which is based on input to the module from parameters supplied to the class. This part reminds me a great deal of the jobs run in some continuous integration solutions, with Jenkins or Hudson in mind if the context helps. I am seeing it much like a perpetually “pending” jenkins job that kicks off during invocation of the class during an agent “run”.
So from here the guide gives you some parameters to add to the class from out of nowhere, like they just fell out of the sky and the user magically knew what they were:
Set the parameters, as follows: gr_web_server = none gr_django_pkg = django gr_django_provider = pip gr_django_ver = "1.5"
For your own betterment, as I said before, when you are writing quality documentation for your own software, it is important with complex systems to never provide options and values without showing how those options and values are obtained first, so that the user can reproduce that type of task for other situations. You want to teach your users how to fish, not give them fish, otherwise it’s not a tutorial or guide — it’s a script that is only applicable to the use case, unfortunately, of walking through that version of that guide and little else. Now in this guide’s case I’m sure they later explain where these parameters and their possible values are coming from, likely in a reference doc for the module itself, but the order of how you present information is also important, and you want to make sure you don’t skip the creation of a skill that is a dependency of another task or skill.
Maybe there’s a command coming that will dump the parameters and their potential values of a class coming up. It has been revealed on IRC that these should be documented in the module.
Ok, I’ll come back to that and add it in when it’s time to compile the guide.
Add the parameters and commit the change. Next, we’re going to run the puppet agent to apply the change. The last operation which installed graphite, was performed by the puppet master and not the agent. My primary concern right now is that I had to install graphite on the master to set up the agent to install it.
The default configuration for the puppet agent is to run every 30 minutes and grabs the whole catalog for it’s node group, and applies any ….facts…..? …resources….? ugh, it applies any configurations not yet applied to make sure the machine’s catalog matches the catalog it received.
root@learning:~ # puppet agent --test
Info: Using configured environment 'production'
Info: Retrieving pluginfacts
Info: Retrieving plugin
Info: Loading facts
Info: Caching catalog for learning.puppetlabs.vm
Info: Applying configuration version '1475438972'
Notice: /Stage[main]/Graphite::Install/Package[django]/ensure: created
Notice: /Stage[main]/Graphite::Install/Package[MySQL-python]/ensure: created
Notice: /Stage[main]/Graphite::Install/Package[pyOpenSSL]/ensure: created
Notice: /Stage[main]/Graphite::Install/Package[pycairo]/ensure: created
Notice: /Stage[main]/Graphite::Install/Package[python-crypto]/ensure: created
Notice: /Stage[main]/Graphite::Install/Package[python-ldap]/ensure: created
Notice: /Stage[main]/Graphite::Install/Package[python-memcached]/ensure: created
Notice: /Stage[main]/Graphite::Install/Package[python-psycopg2]/ensure: created
Notice: /Stage[main]/Graphite::Install/Package[python-zope-interface]/ensure: created
Notice: /Stage[main]/Graphite::Install/Package[python-tzlocal]/ensure: created
Notice: /Stage[main]/Graphite::Install/Package[dejavu-fonts-common]/ensure: created
Notice: /Stage[main]/Graphite::Install/Package[dejavu-sans-fonts]/ensure: created
Notice: /Stage[main]/Graphite::Install/Package[twisted]/ensure: created
Notice: /Stage[main]/Graphite::Install/Package[carbon]/ensure: created
Notice: /Stage[main]/Graphite::Install/Package[django-tagging]/ensure: created
Notice: /Stage[main]/Graphite::Install/Package[graphite-web]/ensure: created
Notice: /Stage[main]/Graphite::Install/Package[whisper]/ensure: created
Notice: /Stage[main]/Graphite::Install/File[carbon_hack]/ensure: created
Notice: /Stage[main]/Graphite::Install/File[gweb_hack]/ensure: created
Info: Class[Graphite::Install]: Scheduling refresh of Class[Graphite::Config]
Info: Class[Graphite::Install]: Scheduling refresh of Exec[Initial django db creation]
Info: Class[Graphite::Config]: Scheduling refresh of Exec[Initial django db creation]
Info: Class[Graphite::Config]: Scheduling refresh of Service[carbon-cache]
Notice: /Stage[main]/Graphite::Config/File[/opt/graphite/webapp/graphite/local_settings.py]/ensure: defined cont
ent as '{md5}c730fd32df46c9baa07c38a6de821626'
Notice: /Stage[main]/Graphite::Config/Exec[Initial django db creation]: Triggered 'refresh' from 2 events
Notice: /Stage[main]/Graphite::Config/File[/opt/graphite/storage]/owner: owner changed 'root' to 'apache'
Notice: /Stage[main]/Graphite::Config/File[/opt/graphite/storage]/group: group changed 'root' to 'apache'
Notice: /Stage[main]/Graphite::Config/File[/opt/graphite/storage/lists]/owner: owner changed 'root' to 'apache'
Notice: /Stage[main]/Graphite::Config/File[/opt/graphite/storage/lists]/group: group changed 'root' to 'apache'
Notice: /Stage[main]/Graphite::Config/File[/opt/graphite/storage/log]/owner: owner changed 'root' to 'apache'
Notice: /Stage[main]/Graphite::Config/File[/opt/graphite/storage/log]/group: group changed 'root' to 'apache'
Notice: /Stage[main]/Graphite::Config/File[/opt/graphite/storage/log/webapp]/owner: owner changed 'root' to 'apache'
Notice: /Stage[main]/Graphite::Config/File[/opt/graphite/storage/log/webapp]/group: group changed 'root' to 'apache'
Notice: /Stage[main]/Graphite::Config/File[/opt/graphite/storage/rrd]/owner: owner changed 'root' to 'apache'
Notice: /Stage[main]/Graphite::Config/File[/opt/graphite/storage/rrd]/group: group changed 'root' to 'apache'
Notice: /Stage[main]/Graphite::Config/File[/opt/graphite/storage/run]/ensure: created
Notice: /Stage[main]/Graphite::Config/File[/opt/graphite/storage/whisper]/owner: owner changed 'root' to 'apache
'
Notice: /Stage[main]/Graphite::Config/File[/opt/graphite/storage/whisper]/group: group changed 'root' to 'apache
'
Notice: /Stage[main]/Graphite::Config/File[/opt/graphite/storage/log/carbon-cache]/ensure: created
Notice: /Stage[main]/Graphite::Config/File[/opt/graphite/storage/graphite.db]/owner: owner changed 'root' to 'apache'
Notice: /Stage[main]/Graphite::Config/File[/opt/graphite/storage/graphite.db]/group: group changed 'root' to 'apache'
Notice: /Stage[main]/Graphite::Config/File[/opt/graphite/conf/graphite.wsgi]/ensure: defined content as '{md5}4714e01760eaec667ccab3bb747397af'
Notice: /Stage[main]/Graphite::Config/File[/opt/graphite/conf/storage-schemas.conf]/ensure: defined content as '{md5}c9e2cc2b133ffe704015d91d4876817e'
Info: /Stage[main]/Graphite::Config/File[/opt/graphite/conf/storage-schemas.conf]: Scheduling refresh of Service
[carbon-cache]
Notice: /Stage[main]/Graphite::Config/File[/opt/graphite/conf/carbon.conf]/ensure: defined content as '{md5}621a284ff9b16a507301bd3fd21d1955'
Info: /Stage[main]/Graphite::Config/File[/opt/graphite/conf/carbon.conf]: Scheduling refresh of Service[carbon-c
ache]
Notice: /Stage[main]/Graphite::Config/File[/opt/graphite/conf/storage-aggregation.conf]/ensure: defined content
as '{md5}9a9a9319750430659ba6b0c938c9655b'
Notice: /Stage[main]/Graphite::Config/File[/opt/graphite/conf/whitelist.conf]/ensure: defined content as '{md5}be63d267d82661b9391dbbe59b55b41c'
Notice: /Stage[main]/Graphite::Config/File[/opt/graphite/conf/blacklist.conf]/ensure: defined content as '{md5}12d3c50b2398a6ba571ed26dc99d169f'
Notice: /Stage[main]/Graphite::Config/File[/opt/graphite/bin/carbon-logrotate.sh]/ensure: defined content as '{md5}4a210d7c1078fd43468801d653013eaf'
Notice: /Stage[main]/Graphite::Config/Cron[Rotate carbon logs]/ensure: created
Notice: /Stage[main]/Graphite::Config/File[/etc/init.d/carbon-cache]/ensure: defined content as '{md5}5a5f12808ff845457f19c5a657837736'
Notice: /Stage[main]/Graphite::Config/Service[carbon-cache]/ensure: ensure changed 'stopped' to 'running'
Info: /Stage[main]/Graphite::Config/Service[carbon-cache]: Unscheduling refresh on Service[carbon-cache]
Notice: Applied catalog in 62.92 seconds
root@learning:~ #
So, it looks like this puts graphite on port 90 of the existing apache instance. Check it out in a web browser.
https://$VM_IP_ADDRESS:90
Also, graphite is amazing if you like building dashboards. Or can be. You can make shiny, highly readable graphs of complex data with it. Or ugly graphs. It depends on your soul.
Getting there.
Next is resources.
quest begin Resources
Resources are in DSL format ……in some file….somewhere….and represent …wait for it, big several paragraphs wind about abstraction that could have been expressed in one sentence….any aspect of your system configuration that you want to manage. So they’re saying users, files, services, packages, and apparently more. Just somewhere.
So, puppet and its modules are basically hooks into system management tools that it is configured to properly interface with in a cross-distro, universal manner. Fair enough since it came from a Java Shop.
They use an object notation format for resources called DSL, or domain specific language. It’s a configuration language, or, a declarative language.
You can see it in action by viewing a resource, in this case the root user, as such:
root@learning:~ # puppet resource user root
user { 'root':
ensure => 'present',
comment => 'root',
gid => '0',
home => '/root',
password => '$1$Ztstkx4U$PnOfzAQrlEqHzywWA1Lmm0',
password_max_age => '99999',
password_min_age => '0',
shell => '/bin/bash',
uid => '0',
}
There you can see it’s displaying the various properties of the root user along with the hash of the password used in /etc/shadow.
Users are just one type of resource. You can view all the resource types puppet supports with:
puppet describe --list
Damn documenting this is taking forever.
The prototype for a resource is:
resourceType { 'resourceTitle':
supportedProperty => value,
}
Looking at the DSL example above, and the examples from the guide, it appears to be type aware (string, int, etc). Not sure how far that goes.
Assignment operators (=>) are being called hash rockets.
Ah. So this will be important. If you want to see the properties you can set for a resource type, let’s say user:
puppet describe user
Interesting. In the description don’t be fooled by the ** surrounding the supportedProperty. So, for instance **roles** when added in is just roles => 'value'.
Puppet describe is very useful to navigate properties, next is puppet apply. Creating a user as a one-liner, for example is done as:
root@learning:~ # puppet apply -e "user { 'galatea': ensure => present, }"
Notice: Compiled catalog for learning.puppetlabs.vm in environment production in 0.04 seconds
Notice: /Stage[main]/Main/User[galatea]/ensure: created
Notice: Applied catalog in 0.48 seconds
root@learning:~ #
And to build up some rote, let’s look at the user we just created:
root@learning:~ # puppet resource user galatea
user { 'galatea':
ensure => 'present',
gid => '1003',
home => '/home/galatea',
password => '!!',
password_max_age => '99999',
password_min_age => '0',
shell => '/bin/bash',
uid => '1003',
}
root@learning:~ #
Useful basic commands.
If you want the kind of behaviour you’d expect from visudo to edit a resource, you can use the -e switch on puppet resource:
root@learning:~ # puppet resource -e user galatea Info: Loading facts Info: Loading facts Info: Loading facts Info: Loading facts Info: Loading facts Info: Loading facts Info: Loading facts Info: Loading facts Notice: Compiled catalog for learning.puppetlabs.vm in environment production in 0.04 seconds Info: Applying configuration version '1475442160' Notice: /Stage[main]/Main/User[galatea]/comment: comment changed '' to 'Galatea of Cyprus' Notice: Applied catalog in 0.53 seconds root@learning:~ #
After you run the above command, a vi session opens with the resource in DSL format, you can make on the fly changes to the properties, in my case, per the guide, I added a missing comment property that was supported but not required, saved the file, and it reshaped the resource to the new state.
Looking like they’re weening you onto the CLI for some reason. It could be to showcase the enterprise-specific UIs.
Next quest, manifests and classes.
I have a sweet, sweet feeling we’re about to get off the enterprise-specific features and set up a class manually.
A manifest is a collection of DSL/puppet code code. When we went into the visudo mode earlier and edited the user, that was a manifest file. Resection this explanation.
A class is a named block of DSL/puppet code. It’s the next level of abstraction above a resource.
So, manifests contain classes which are sets of resources.
Classes must be unique on a node.
Next we’ll define a class.
The guide says to go to:
cd /etc/puppetlabs/code/environments/production/modules
If you look at the above directory where I’ve highlighted, this is interesting. This is the code directory that had stuff jammed into it a few posts back when I was trying to follow the “install from module” path and failing hard at it.
While getting there I noticed that there were actually two modules directories under the /etc/puppetlabs tree:
/etc/puppetlabs/code/modules /etc/puppetlabs/code/environments/production/modules
But without the guide revisiting I won’t know what their difference in purposes are other than that one is environment-specific in the puppet context.
The purpose of this lesson is to install an OS package called “cowsay”.
With the current working directory to be the production modules directory, it is saying to create cowsayings/manifests/cowsay.pp:
vim cowsayings/manifests/cowsay.pp
This is not accurate as the next step. You must first create the parent directories to put a file into the bottom-level directory or vim will tell you it can’t open the file for writing. The cowsayings/manifests/ directories don’t exist, so create them:
root@learning:/etc/puppetlabs/code/environments/production/modules # mkdir -p cowsayings/manifests
root@learning:/etc/puppetlabs/code/environments/production/modules # ll
total 20
drwxr-xr-x 7 root root 4096 Sep 23 14:06 concat
drwxr-xr-x 3 root root 22 Oct 2 16:24 cowsayings
drwxr-xr-x 9 root root 4096 Sep 23 14:06 docker
drwxr-xr-x 8 root root 4096 Sep 23 14:06 dockeragent
drwxr-xr-x 5 pe-puppet pe-puppet 4096 Jan 29 2016 graphite
drwxr-xr-x 6 root root 4096 Sep 23 14:06 stdlib
root@learning:/etc/puppetlabs/code/environments/production/modules #
I copied the class from the guide:
class cowsayings::cowsay {
package { 'cowsay':
ensure => present,
provider => 'gem',
}
}They’ve got syntax validation for newly created manifest files:
puppet parser validate cowsayings/manifests/cowsay.pp
Which returns nothing.
So they’re using a define/declare model with these classes. At this point we just defined it. Not sure what the rules are for that directory tree yet, either.
I’m not in full understanding yet, but create an examples directory in the cowsayings tree root:
root@learning:/etc/puppetlabs/code/environments/production/modules # mkdir cowsayings/examples root@learning:/etc/puppetlabs/code/environments/production/modules # vim cowsayings/examples/cowsay.pp
Next add a single line to the file and save it:
include cowsayings::cowsay
Then apply the…examples file…which they are saying is by convention to declare a file. These are test manifests.
And let’s apply our test manifest:
root@learning:/etc/puppetlabs/code/environments/production/modules # puppet apply --noop cowsayings/examples/cowsay.pp Notice: Compiled catalog for learning.puppetlabs.vm in environment production in 1.14 seconds Notice: /Stage[main]/Cowsayings::Cowsay/Package[cowsay]/ensure: current_value absent, should be present (noop) Notice: Class[Cowsayings::Cowsay]: Would have triggered 'refresh' from 1 events Notice: Stage[main]: Would have triggered 'refresh' from 1 events Notice: Applied catalog in 0.70 seconds root@learning:/etc/puppetlabs/code/environments/production/modules #
I used the –noop as directed by the guide. This is the dry run option.
Looks good, so remove the –noop option and run it again. It should have installed cowsay using gem.
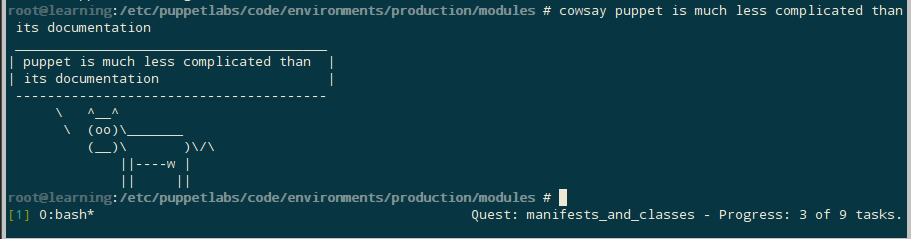
It worked.
Next it wants to add the fortune-mod package:
class cowsayings::fortune {
package { 'fortune-mod':
ensure => present,
}
}
And let’s create an example manifest for that as cowsayings/examples/fortunes.pp with a similar include line:
include cowsayings::fortune
Save, check, apply:
root@learning:/etc/puppetlabs/code/environments/production/modules # puppet apply --noop cowsayings/examples/fortune.pp Notice: Compiled catalog for learning.puppetlabs.vm in environment production in 0.85 seconds Notice: /Stage[main]/Cowsayings::Fortune/Package[fortune-mod]/ensure: current_value purged, should be present (noop) Notice: Class[Cowsayings::Fortune]: Would have triggered 'refresh' from 1 events Notice: Stage[main]: Would have triggered 'refresh' from 1 events Notice: Applied catalog in 0.62 seconds root@learning:/etc/puppetlabs/code/environments/production/modules # puppet apply cowsayings/examples/fortune.pp Notice: Compiled catalog for learning.puppetlabs.vm in environment production in 0.84 seconds Notice: /Stage[main]/Cowsayings::Fortune/Package[fortune-mod]/ensure: created Notice: Applied catalog in 3.00 seconds root@learning:/etc/puppetlabs/code/environments/production/modules #
And it is good.
You can test it out by running fortune. The guide pipes fortune to cowsay, you could do that too.
So, it looks like puppet apply is scanning that modules directory for a module named cowsayings, which in the class name in the files under that same cowsayings directory name is being used as a kind of namespace in the DSL.
Yep, the scope syntax on the class name tells puppet where to find that class, which according to the namespace in the class name is the cowsayings module.
$moduleName::$className {}
references
/etc/puppetlabs...modules/${moduleName}/manifests/${className}.pp
are now givens if I’m reading that correctly.
There is a ‘main class’ for modules which will always share the name of the module, in this case ‘cowsayings’, but must reside in ${moduleName}/manifests/init.pp.
In notably good practice, it looks like they’re hoping you’ll build the init manifest from the includes lines created in the example manifests:
class cowsayings {
include cowsayings::cowsay
include cowsayings::fortune
}
Which is a good, structured way to do that (ffs, they could have just screenshotted the output of tree on an atomic module and communicated all of that).
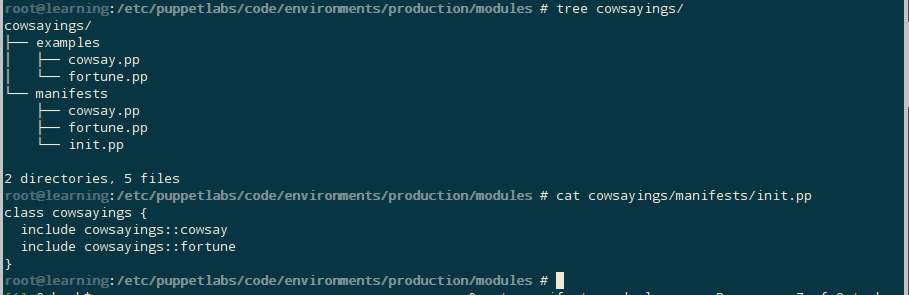
Good practice, run parser against all your .pp files.
Now we’re going to remove the packages again so we can run our new module:
root@learning:/etc/.../modules # puppet resource package fortune-mod ensure=absent
Notice: /Package[fortune-mod]/ensure: removed
package { 'fortune-mod':
ensure => 'purged',
}
root@learning:/etc/.../modules #
root@learning:/etc/.../modules # puppet resource package cowsay ensure=absent provider=gem
Notice: /Package[cowsay]/ensure: removed
package { 'cowsay':
ensure => 'absent',
}
Good.
Oi, jiminey crickets, they want a text manifest for init.pp now. Create a cowsayings/examples/init.pp with a line just including the class name:
include cowsayings
Sure we don’t need a test for our test? Or maybe a test for our test for our test?
At this point you know how to apply a manifest as a dry run.
So how far along are we?
About 40%. Yeah, really. What a needlessly complicated thing this has turned out to be. I’m just exhausted, I can’t believe it, this will have to wait another day. I’m like two weeks behind schedule with this now.
With a common distro on all servers, everything done here so far could have been scripted out to a listening agent on the nodes, with a single configuration file or database driving it if I had built a framework myself.
What’s up with the docs, though? I’m kind of ranting before bed, but, it really seems like this content could have been covered with a couple pictures and a few paragraphs so far.